
An Introduction to Programming with Threads
2024-04-13 20:00:00
I didn't feel comfortable programming with threads until I read "An Introduction to Programming with Threads" by Andrew D. Birrell. The patterns from the paper have stuck with me and I often use them to think about system design at work. Usually, when I talk about these things, no one at work knows what I'm talking about. For that reason, I've been thinking about doing a series of posts covering the patterns, and how they extend to current threading libraries and modern distributed environments.
This post supplements the paper, read them side-by-side. The paper introduces some basic thread patterns and a high-level thread library that is in Modula-2+. I'm going to take each example from the paper and show how they map to C++ standard threads. This post is not a deep dive into the C++ threading and memory model. Also, I wanted to keep the code close to the samples in the paper so that the comparison is clear. Please look past the global and subscript variables.
Thread creation
The simplest way to do this is to pass a function as a parameter. We can then join on the function to wait for completion or detach that is equivalent to Fork from the paper.
#include <cstdint>
#include <thread>
#include <iostream>
#include <limits>
#include <chrono>
using namespace std;
void loopUntil(int x){
for(int i = 0; i < x; i++){
cout << i << endl;
}
}
void loopUntilDetached(int x){
for(int i = 0; i < x; i++){
cout << "detached " << i << endl;
}
}
int main(){
thread t(loopUntil, 20);
thread t2(loopUntilDetached, INT32_MAX);
t.join();
cout << "detaching second thread" << endl;
t2.detach();
for(int i = 0; i < 1000; i++){
cout << "testing: " << i << endl;
}
//give the detached thread some time to run
this_thread::sleep_for(chrono::seconds(5));
}
Mutual exclusion
Here, the global mutex locks the list structure. It mimics the LOCK m DO construct from the paper.
#include <thread>
#include <mutex>
#include <iostream>
#include <vector>
using namespace std;
vector<int> v;
mutex m;
void addFrom(int start){
m.lock();
for(int i = 0; i < 10; i++){
v.push_back(i + start);
}
m.unlock();
}
int main(){
thread t1(addFrom, 0);
thread t2(addFrom, 100);
t1.join();
t2.join();
for(auto x : v){
cout << x << endl;
}
return 0;
}
Conditional variables
The C++ std::condition_variable aligns with the section of the paper with the same name.
| Birrell | C++ |
|---|---|
Wait(m: Mutex; c: Condition) | wait(unique_lock |
Signal(c: Condition) | notify_one() |
Broadcast(c: Condition) | notify_all() |
#include <thread>
#include <mutex>
#include <iostream>
#include <vector>
#include <condition_variable>
#include <chrono>
using namespace std;
vector<int> *v = nullptr;
mutex m;
condition_variable nonEmpty;
void addFrom(int start){
unique_lock<mutex> lck(m);
cout << "waiting" << endl;
nonEmpty.wait(lck, []{ return v != nullptr;});
cout << "initalized" << endl;
for(int i = 0; i < 10; i++){
v->push_back(i + start);
}
}
void init(){
unique_lock<mutex> lck(m);
cout << "initalizing" << endl;
v = new vector<int>();
lck.unlock();
nonEmpty.notify_one();
}
int main(){
thread t2(addFrom, 0);
std::this_thread::sleep_for (std::chrono::seconds(1));
thread t1(init);
t1.join();
t2.join();
for(auto x : *v){
cout << x << endl;
}
return 0;
}
Alerts
It looks like C++ introduced an alert mechanism in C++20 that I'll need to explore. Birrell states, "Alerts are complicated, and their use produces complicated programs."
Unprotected Data Example
On Page 7 he covers the use of a mutex again in more detail. If you're curious about REFANY, modula-2+ had traced and untraced allocations. Untraced allocations were not garbage collected.
#include <string>
#include <iostream>
#include <thread>
//Birrell Introduction to Threads
//ex. page 7
using namespace std;
typedef struct person_t {
string fname;
string lname;
} person_t;
person_t *table[999] = {0};
int i;
void insert(person_t *person){
if (person != nullptr){
table[i] = person;
i++;
}
}
person_t *makePerson(string fname, string lname){
person_t *p = new person_t();
p->fname = fname;
p->lname = lname;
return p;
}
void insertX(){
insert(makePerson("person", "X"));
}
void insertY(){
insert(makePerson("person", "Y"));
}
int main(){
thread t1(insertX);
thread t2(insertY);
t1.join();
t2.join();
cout << "i = " << i << endl;
for(int j = 0; j < 2; j++){
if (table[j] == nullptr){
cout << j << " is null " << endl;
} else {
person_t *p = table[j];
cout << j << " " << p->fname << " " << p->lname << endl;
}
}
return 0;
}
The code above can duplicate the unpredictable behavior explained in the paper. We lose Person Y on the 2nd run below.
[jeng@cboss threads]$ clang++ unprotected_data.cpp
[jeng@cboss threads]$ ./a.out
i = 2
0 person X
1 person Y
[jeng@cboss threads]$ ./a.out
i = 1
0 person X
1 is null
Let's introduce the fix:
void insert(person_t *person){
m.lock();
if (person != nullptr){
table[i] = person;
i++;
}
m.unlock();
}
Looks good, in 100 runs of the program we go from having 11 cases of an orphan record to zero.
[jeng@cboss threads]$ for i in {1..100}; do ./a.out; done | grep null | wc
11 33 121
[jeng@cboss threads]$ clang++ unprotected_data.cpp
[jeng@cboss threads]$ for i in {1..100}; do ./a.out; done | grep null | wc
0 0 0
Is this quote still true: "It would be a good idea for your language system to give you some help here, for example by syntax that prevents you accessing variables until you have locked the appropriate mutex. But most languages don't offer this yet."?
Invariants
Today, for formal specification you would use something like TLA+. Leslie Lamport has published a draft version of his new book.
Cheating
Birrell mentions that you can skip a mutex if you know the operation happened with an atomic operation. Assumptions need to be made about the architecture to make sure the code is executing as you anticipated. To avoid guessing, today we can use intrinsics and force the use of atomics.
Deadlocks involving only mutexes

#include <thread>
#include <mutex>
#include <iostream>
#include <vector>
using namespace std;
vector<int> v;
mutex m1;
mutex m2;
void A(){
m1.lock();
std::this_thread::sleep_for(std::chrono::seconds(1));
m2.lock();
for(int i = 0; i < 10; i++){
v.push_back(i);
}
m1.unlock();
m2.unlock();
}
void B_deadlock(){
m2.lock();
std::this_thread::sleep_for(std::chrono::seconds(1));
m1.lock();
for(int i = 100; i < 110; i++){
v.push_back(i);
}
m2.unlock();
m1.unlock();
}
void B_corrected(){
m1.lock();
std::this_thread::sleep_for(std::chrono::seconds(1));
m2.lock();
for(int i = 100; i < 110; i++){
v.push_back(i);
}
m1.unlock();
m2.unlock();
}
int main(){
thread t1(A);
//thread t2(B_deadlock);//runs forever
thread t2(B_corrected);//locks are in a matching order now
t1.join();
t2.join();
for(auto x : v){
cout << x << endl;
}
return 0;
}
The timing diagram above illustrates the example given in the paper. Uncomment the B_deadlock line to simulate this. The fix is to make sure you always lock the mutexes in the same order. If the threads can work on disjoint sections of a large memory region, the lock is not needed. I'll show an example when exploring ray tracers in a future post.
Poor performance through lock conflicts
When using ifstream it relies on the underlying C library that is using a FILE object. FILE objects have a lockcount that provides thread safety. For more information on this, see the man page for flockfile. With a 500 line test file, we see unpredictable output even with the lockcount.
Output:
139642961630784 t4 225
139642961630784 t4 225
139642961630784 t4 225
139642953238080 224
139642961630784 t4 225
139642953238080 224
139642953238080 224
139642961630784 t4 225
Adding the individual file mutexes corrects this.
Port of example code from page 11:
#include <fstream>
#include <thread>
#include <mutex>
#include <iostream>
#include <vector>
#include <sstream>
using namespace std;
struct file_t {
ifstream *stream;
mutex m;
};
vector<file_t*> files;
mutex globalFilesLock;
mutex bufferMutex;
vector<string> buffer;
void saveToBuffer(string s){
bufferMutex.lock();
buffer.push_back(s);
bufferMutex.unlock();
}
void openfile(string fname){
file_t *f = new file_t();
f->stream = new ifstream(fname, ifstream::in);
globalFilesLock.lock();
files.push_back(f);
globalFilesLock.unlock();
}
void readfile(file_t *file){
string f;
string id;
auto tid = std::this_thread::get_id();
stringstream ss;
ss << tid;
string stid = ss.str();
file->m.lock();
for(int i = 0; i < 250; i++){
*file->stream >> f >> id;
saveToBuffer(stid + " " + f + " " + id);
}
file->m.unlock();
}
int main(){
thread t1(openfile, "t1.txt");
thread t2(openfile, "t2.txt");
thread t3(openfile, "t3.txt");
thread t4(openfile, "t4.txt");
t1.join();
t2.join();
t3.join();
t4.join();
thread t5(readfile, files[0]);
thread t6(readfile, files[0]);
thread t7(readfile, files[1]);
thread t8(readfile, files[1]);
thread t9(readfile, files[2]);
thread t10(readfile, files[2]);
thread t11(readfile, files[3]);
thread t12(readfile, files[3]);
t5.join();
t6.join();
t7.join();
t8.join();
t9.join();
t10.join();
t11.join();
t12.join();
for(auto x : buffer){
cout << x << endl;
}
return 0;
}
Thread priority impact to performance

The std thread library does not provide a way to set the thread's priority. To duplicate the issue covered in the paper, you would need a single core vm. Then use a system library and SetThreadPriority on Windows or pthread setschedprio on Linux to control the thread priority.
Scheduling Shared Resources
After the thread gets the signal, we need to check the condition again to avoid race conditions. Be sure to read the section related to the while loop in the paper.
#include <condition_variable>
#include <iostream>
#include <mutex>
#include <thread>
using namespace std;
struct node_t {
int n;
node_t *next;
};
mutex m;
node_t *head = nullptr;
condition_variable cv;
bool headNotNull(){
return head != nullptr;
}
void consume(node_t &topElement){
unique_lock<mutex> lck(m);
while (head == nullptr)
cv.wait(lck, headNotNull);
topElement = *head;
head = head->next;
}
void produce(node_t *newElement){
unique_lock<mutex> lck(m);
newElement->next = head;
head = newElement;
cv.notify_one();
}
int main(){
node_t c1 = {0};
node_t c2 = {0};
node_t p1 = {1, nullptr};
node_t p2 = {2, nullptr};
node_t p3 = {3, nullptr};
thread t1(consume, std::ref(c1));
thread t2(consume, std::ref(c2));
thread t3(produce, &p1);
thread t4(produce, &p2);
thread t5(produce, &p3);
t1.join();
t2.join();
t3.join();
t4.join();
t5.join();
cout << c1.n << " " << c2.n << " " << head->n << endl;
}
What happens if we remove the notification notify_one? The program will hang since we never come out of the wait state. The standard library also has wait_until to handle a case when you're not sure when a notification will fire:
void consume(node_t &topElement){
unique_lock<mutex> lck(m);
chrono::time_point<chrono::system_clock> timepoint =
chrono::system_clock::now() + chrono::seconds(30);
while (head == nullptr){
if (!cv.wait_until(lck, timepoint, headNotNull)){
cerr << "Timed out waiting for list item" << endl;
exit(1);
}
}
topElement = *head;
head = head->next;
}
The paper says we need the while loop, but the conditional variable's wait takes a predicate. Do we still need the while loop? Let's make the following changes:
void consume(node_t &topElement){
unique_lock<mutex> lck(m);
cv.wait(lck, headNotNull);
this_thread::sleep_for(chrono::seconds(2));
topElement = *head;
head = head->next;
}
void produce(node_t *newElement){
unique_lock<mutex> lck(m);
newElement->next = head;
head = newElement;
cv.notify_one();
lck.unlock();
//Evil code...
this_thread::sleep_for(chrono::seconds(1));
lck.lock();
head = nullptr;
lck.unlock();
}
This code generates a segmentation fault. The head is being set to null between leaving the wait and dereferencing head. The while loop keeps unanticipated errors like this from happening.
I'm going to do some code spelunking in a future post and look into the wait and wait_until implementations. I'd also like to dig deeper into the comment in the paper about Hoare's original design.
Another thing you may have noticed is that I'm passing an explicit ref to the consumer to get a copy of the return value. The standard library also provides futures and promises that provide a succinct way to get return values.
Using Broadcast (notify_all)

#include <vector>
#include <condition_variable>
#include <iostream>
#include <mutex>
#include <thread>
using namespace std;
int i;
mutex m;
condition_variable cv;
mutex output;
vector<int> buffer;
void acquireExclusive(){
unique_lock<mutex> lck(m);
while(i != 0){
cv.wait(lck);
}
i--;
}
void acquireShared(){
unique_lock<mutex> lck(m);
while(i < 0){
cv.wait(lck);
}
i++;
}
void releaseExclusive(){
unique_lock<mutex> lck(m);
i = 0;
cv.notify_all();
}
void releaseShared(){
unique_lock<mutex> lck(m);
i--;
if (i == 0)
cv.notify_one();
}
void print(string s){
output.lock();
cout << s << endl;
output.unlock();
}
void reader(){
acquireShared();
string s = "reader: ";
for(int x : buffer){
s = s + to_string(x) + " ";
}
releaseShared();
print(s);
}
void writer(){
acquireExclusive();
int x = buffer.size();
buffer.push_back(buffer.size());
releaseExclusive();
print("writer: " + to_string(x));
}
int main(){
std::srand(std::time(nullptr)); // use current time as seed for random generator
int numThreads = (std::rand() % 75) + 25;
vector<thread*> threads;
for(int i = 0; i < numThreads; i++){
int roll = std::rand() % 6;
if (roll < 3){
thread *t = new thread(reader);
threads.push_back(t);
}else {
thread *t = new thread(writer);
threads.push_back(t);
}
}
for(int i = 0; i < threads.size(); i++){
threads[i]->join();
}
for(int i = 0; i < threads.size(); i++){
free(threads[i]);
}
return 0;
}
The implementation in the paper favors readers, this is the First readers-writers problem
As a slight diversion, the C++20 standard library also provides semaphores. We can use semaphores to implement a solution to the First readers-writers problem too. This is a port from Operating System Concepts
#include <vector>
#include <iostream>
#include <semaphore>
#include <mutex>
#include <thread>
using namespace std;
int readCount = 0;
binary_semaphore m{1};
binary_semaphore wrt{1};
mutex output;
vector<int> buffer;
void print(string s){
output.lock();
cout << s << endl;
output.unlock();
}
void reader(){
m.acquire();
readCount++;
if (readCount == 1)
wrt.acquire();
m.release();
string s = "(s)reader: ";
for(int x : buffer){
s = s + to_string(x) + " ";
}
print(s);
m.acquire();
readCount--;
if (readCount == 0)
wrt.release();
m.release();
}
void writer(){
wrt.acquire();
int x = buffer.size();
buffer.push_back(buffer.size());
wrt.release();
print("(s)writer: " + to_string(x));
}
int main(){
std::srand(std::time(nullptr)); // use current time as seed for random generator
int numThreads = (std::rand() % 75) + 25;
vector<thread*> threads;
for(int i = 0; i < numThreads; i++){
int roll = std::rand() % 6;
if (roll < 3){
thread *t = new thread(reader);
threads.push_back(t);
}else {
thread *t = new thread(writer);
threads.push_back(t);
}
}
for(int i = 0; i < threads.size(); i++){
threads[i]->join();
}
for(int i = 0; i < threads.size(); i++){
free(threads[i]);
}
return 0;
}
Validation
How are we sure the reads are happening concurrently? So far, I've been compiling the code using clang++ but Visual Studio has a concurrency visualizer tool that can help us see what is going on.
On the first run of the tool we see some weird results:
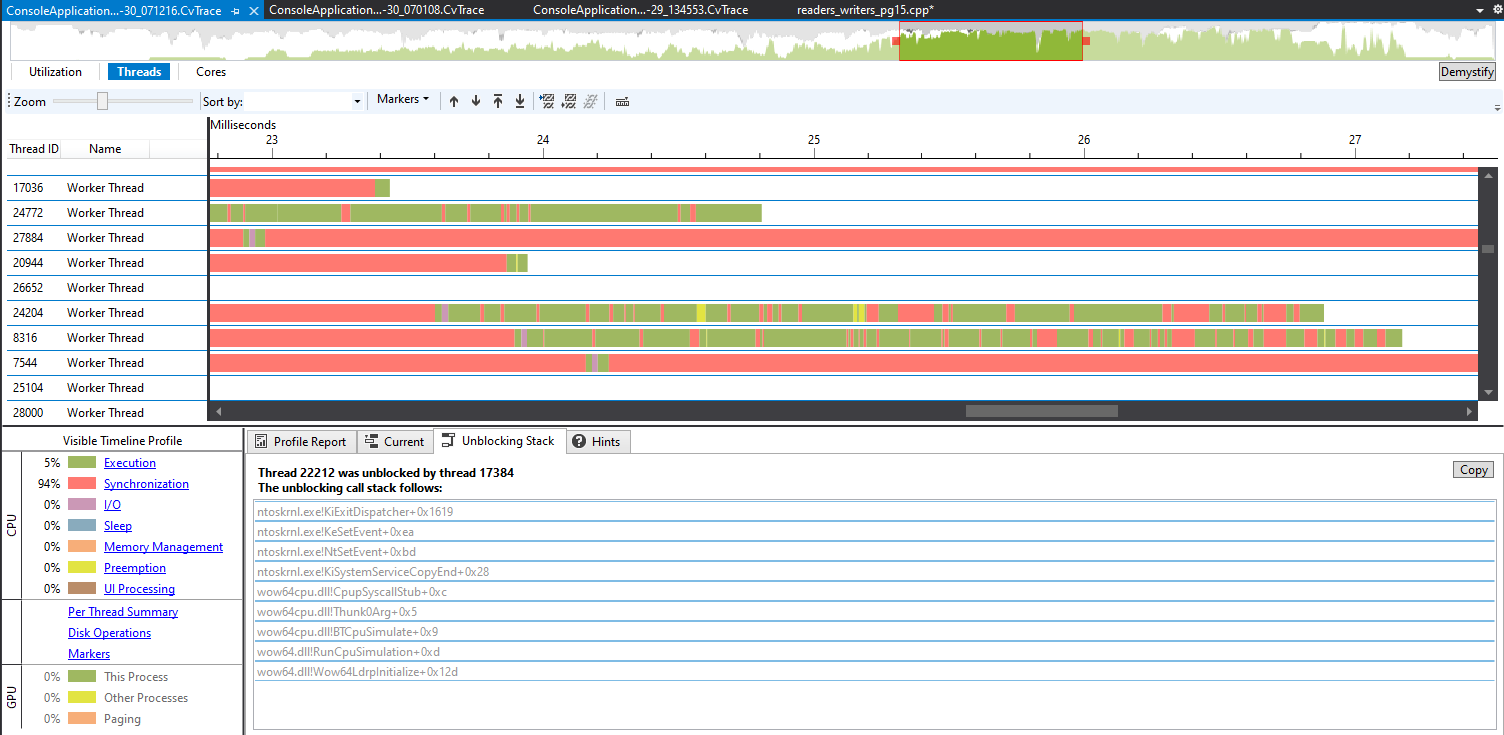
On the bottom left it shows 94% of the time is spent in Synchronization. That doesn't sound good. Let's see if notify and notify_all are working as we expect by looking at an unblocking stack.
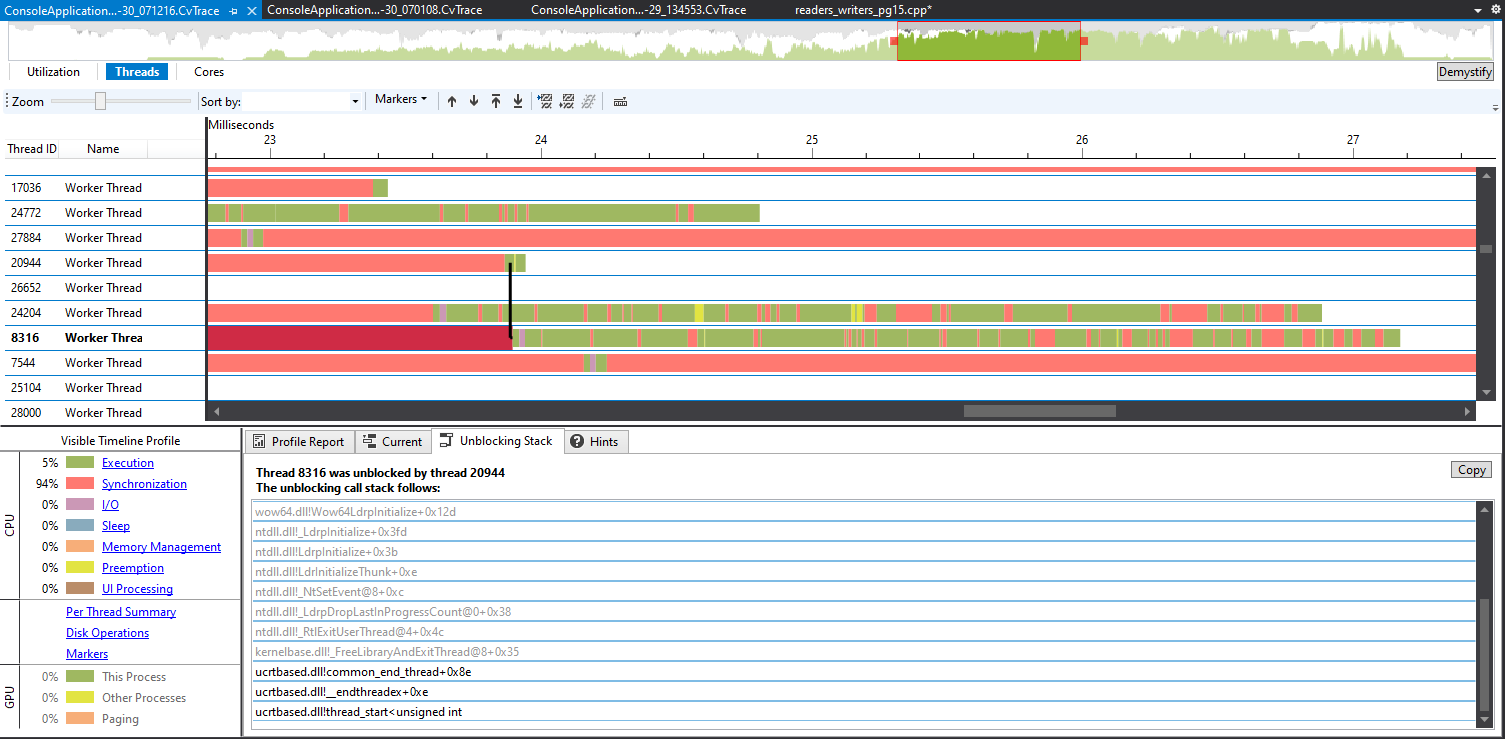
The thread is woken up by common_end_thread, why?
Let's make some minor changes to the original reader/writer example to make visualization a little nicer.
In main change the numThreads to 6 and remove the random decision that sets a thread as reader or writer:
int numThreads = 6;
vector<thread*> threads;
for(int i = 0; i < numThreads; i++){
//int roll = std::rand() % 6;
if (i > 3){
thread *t = new thread(reader);
threads.push_back(t);
}else {
thread *t = new thread(writer);
threads.push_back(t);
}
}
The last change is to make the writer do more work so we have a longer execution time to view in the timing diagram. Let's also comment out the print statements.
void writer(){
acquireExclusive();
for (int i = 0; i < 1000; i++) {
buffer.push_back(buffer.size());
}
releaseExclusive();
//print("writer: " + to_string(x));
}
That is better. Now we can see that we have two readers executing concurrently:
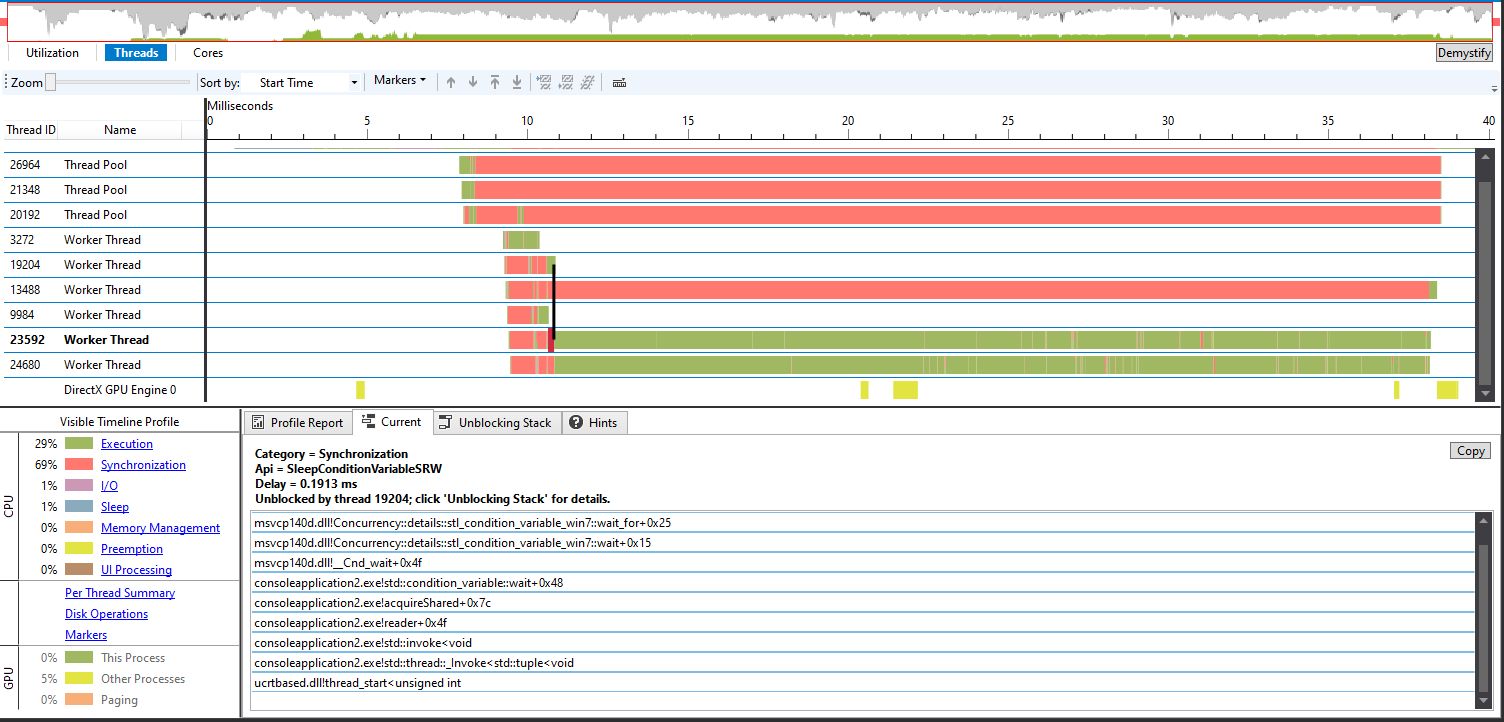
Also notice that they were both unblocked by notify_all in a writer thread:
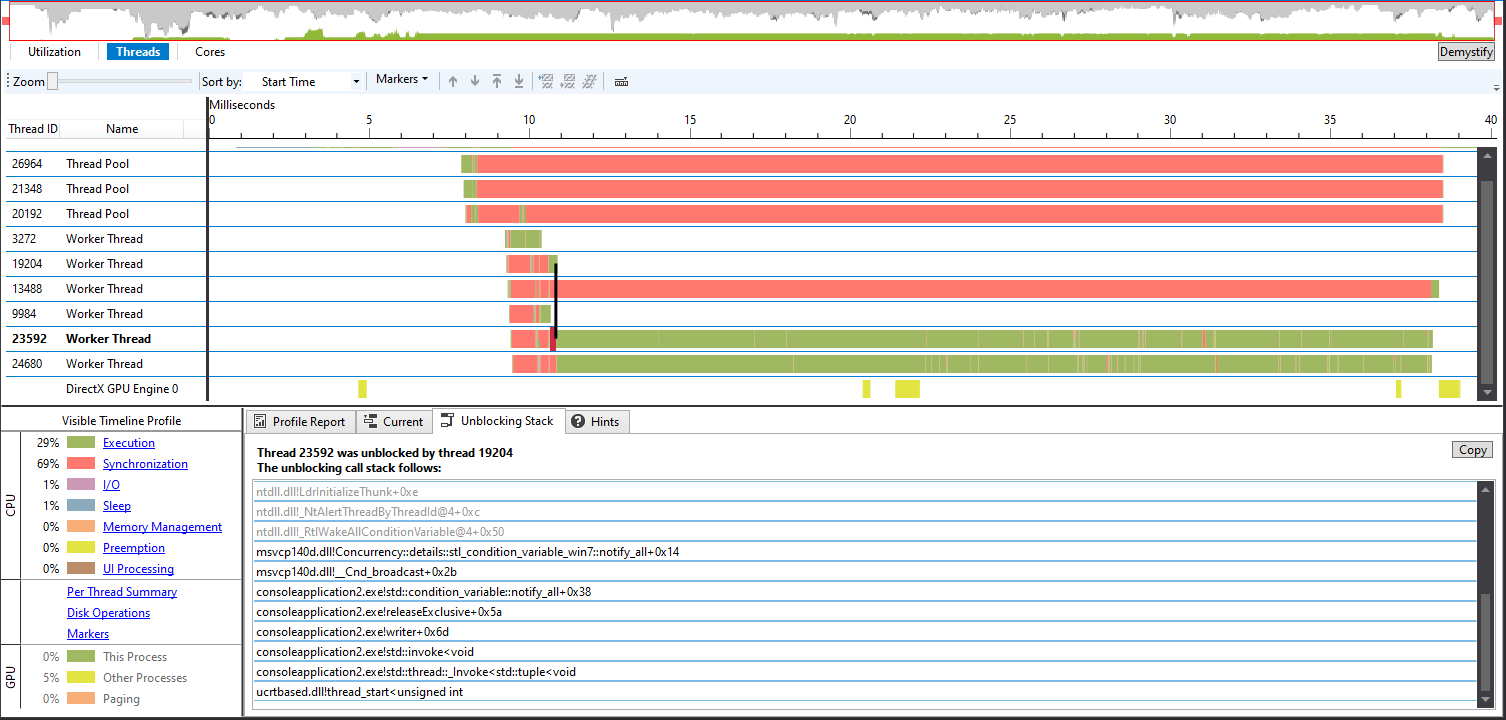
A writer thread is also waiting for a notification from these readers:
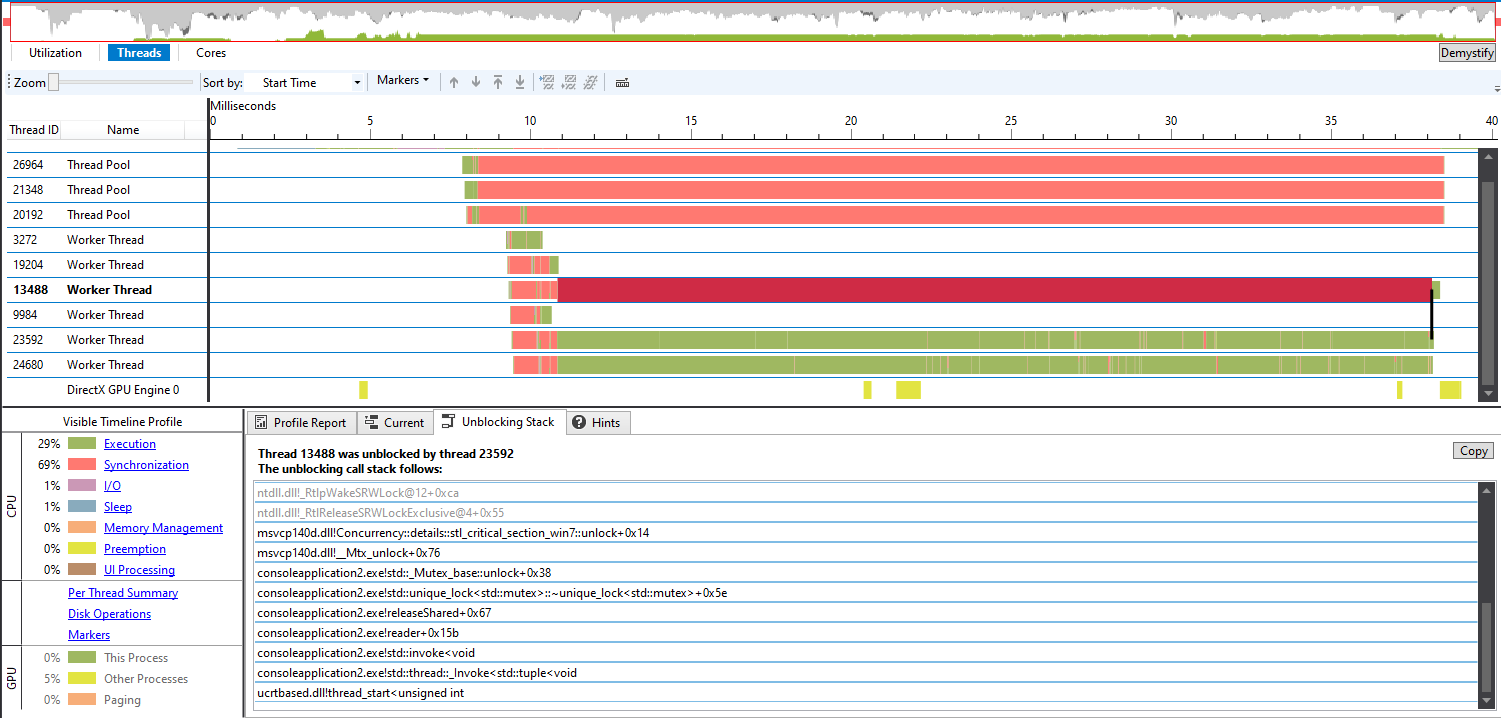
Spurious wake-ups
What we saw above, where the thread tries to execute but the scheduler cannot schedule it so it moves back to the waiting state, is a spurious wake up. If you're interested in learning more about what is going on there look up information by David B. Probert, PhD.
Birrell goes through a couple of reader/writer changes that can be implemented by changing the C++ example above. If you want to read more about reader/writers, the FreeBSD kernel references Spin-based Reader-Writer Synchronization for Multiprocessor Real-Time Systems by Brandenburg, B. and Anderson, J. 2010. It appears Linux is using RCU instead of reader-writer locks.
Using Fork (detach)
In this part of the paper, we start to see patterns that can be extended to distributed systems.
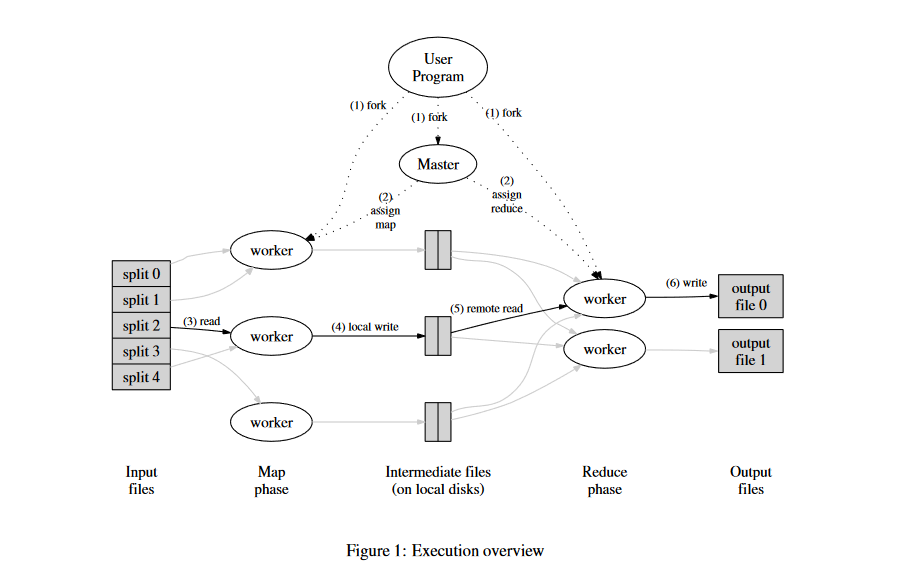
"Often, it is preferable to keep a single housekeeping thread and feed requests to it. It's even better when the housekeeper doesn't need any information from the main threads, beyond the fact that there is work to be done." I learned this as the Boss/Worker pattern but it has a few different names. Birrell calls them Work Crews under the Additional Techniques section. In this diagram from the Mapreduce Paper it is called Master/Worker:
Pipelining
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <queue>
#include <condition_variable>
#ifdef _WIN32
#include <conio.h>
#else
#include <stdio.h>
#endif
using namespace std;
typedef string bitmap_t;
queue<char> raster_list;
queue<bitmap_t> paint_list;
mutex m;
condition_variable c1, c2;
const int MAX_SEVEN_SEG = 96;
extern const uint8_t SevenSegmentASCII[MAX_SEVEN_SEG];
const int LED_WIDTH = 3;
const int LED_HEIGHT = 3;
// __0_
// 5 1
// |__6_|
// 4 2
// |__3_|
//bit nums
void getSevenSegment(char c, bitmap_t &result){
uint8_t x = c - ' ';
int row[7] = {0, 1, 2, 2, 2, 1, 1};
int col[7] = {1, 2, 2, 1, 0, 0, 1};
char sym[] = {'_', '|', '|', '_', '|', '|', '_'};
result.clear();
for(int i = 0; i < LED_WIDTH * LED_HEIGHT; i++){
result += ' ';
}
if (x < MAX_SEVEN_SEG){
uint8_t b = SevenSegmentASCII[x];
for(int i = 0; i < 7; i++){
if (b & 0x1){
result[(row[i] * LED_WIDTH) + col[i]] = sym[i];
}
b >>= 1;
}
}
}
void paintChar(char arg){
unique_lock<mutex> lock(m);
raster_list.push(arg);
c1.notify_one();
}
void rasterize(){
while(true){
//wait for raster_list request and dequeue it
char c;
{
unique_lock<mutex> lock(m);
while(raster_list.size() == 0){
c1.wait(lock);
}
c = raster_list.front();
raster_list.pop();
}
//convert char to bitmap;
bitmap_t bm;
getSevenSegment(c, bm);
//enqueue request for painter thread
{
unique_lock<mutex> lock(m);
paint_list.push(bm);
}
c2.notify_one();
}
}
void painter(){
int lines = 40;
queue<bitmap_t> history;
while(true){
//wait for painter_list request and dequeue it
bitmap_t b;
{
unique_lock<mutex> lock(m);
while(paint_list.size() == 0){
c2.wait(lock);
}
b = paint_list.front();
paint_list.pop();
}
//paint the bitmap
history.push(b);
if(history.size() > lines){
history.pop();
}
//Add the char to the banner
string line[LED_HEIGHT];
for(int i = 0; i < history.size(); i++){
bitmap_t b = history.front();
for(int i = 0; i < LED_HEIGHT; i++){
for(int j = 0; j < LED_WIDTH; j++){
line[i] += b[(i * LED_WIDTH) + j];
}
}
history.push(b);
history.pop();
}
//display banner
for(auto s: line){
cout << s << endl;
}
}
}
int main(){
thread raster_thread(rasterize);
thread painter_thread(painter);
raster_thread.detach();
painter_thread.detach();
string line;
bitmap_t result;
while(true){
#ifdef _WIN32
#pragma warning(suppress : 4996)
char c = getch();
paintChar(c);
#else
system("stty raw");
char c = getchar();
system("stty cooked");
if (c == '~')
exit(0);
paintChar(c);
#endif
}
return 1;
}
The raster step converts the char to a seven-segment display. You'll need to paste this table after main. The paint step updates the banner with the next raster char and prints the banner to stdout.
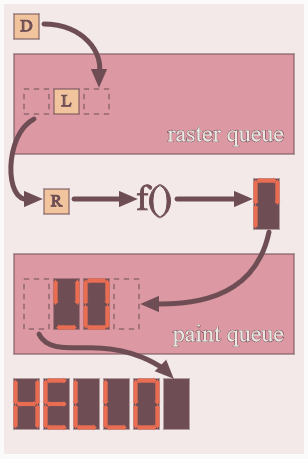
Alerting
Killing a thread or a fork could have unexpected consequences. I can understand why the C++ standard library doesn't really have a mechanism for this under std::thread. This also can branch off into discussions on Supervisors and the Actor model. Watch this talk by Joe Armstrong, the creator of Erlang, for more information on Supervisors.
Additional Techniques
Up-calls
Peter Schafhalter has a good summary on upcalls
Version Stamps
Based on How Netflix microservices tackle dataset pub-sub they are using "up-calls" (via publishing) and versioning to allow subscribers to get the latest version of the data.
Work crews
Having a fixed number of workers and some type of controller is common to many systems today such as Kubernetes, XFaaS, Apache, etc. They're also called Thread Pools.
Conclusion
Some early computer science papers still have relevant and current information. Modern threading libraries have the same functionality as the Birrell paper and the code can be easily ported from its Modula-2+ trappings.