
Embarrassingly Parallel
2024-05-05 10:30:00
This is part 2 of a series based on thread design patterns. Part 1 covers thread features that are available in most libraries and some thread patterns at a high level. This part will cover Thread Pools and the Boss Worker patterns using a Ray Tracer as an example.
Partitioning the Ray Tracer
I'm not sure who first got embarrassed by a program getting wins (or loses) from parallelism but Birrell states:
There are situations that are best described as "an embarrassment of parallelism", when you can structure your program to have vastly more concurrency than can be efficiently accommodated on your machine.
This is a little different from my understanding which aligns more with Wikipedia:
In parallel computing, an embarrassingly parallel workload or problem is one where little or no effort is needed to separate the problem into a number of parallel tasks. This is often the case where there is little or no dependency or need for communication between those parallel tasks, or for results between them.
Ray Tracers are one such type of program. At a high level, the scene is divided into sections, an eye or camera passes a ray through that section, and a color is recorded based on what the ray traversal returns. The internet has tons of high level info on the process. The classic diagram is something similar to the one below. This image was created by CobbleTrace the cpu based ray tracer we will be exploring.
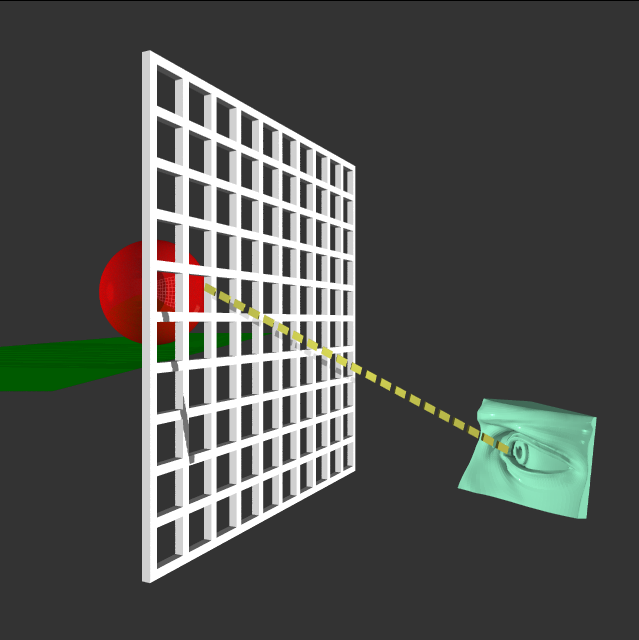
To multithread the program, one thing we could do is to treat each pixel as a section that a ray passes through and assign a thread to each section. This definitely gets into the realm of "more threads than my machine can accommodate" since even a small image would need thousands of threads. Another option is to have a fixed thread pool and partition regions of the scene and assign these partitions to each thread.
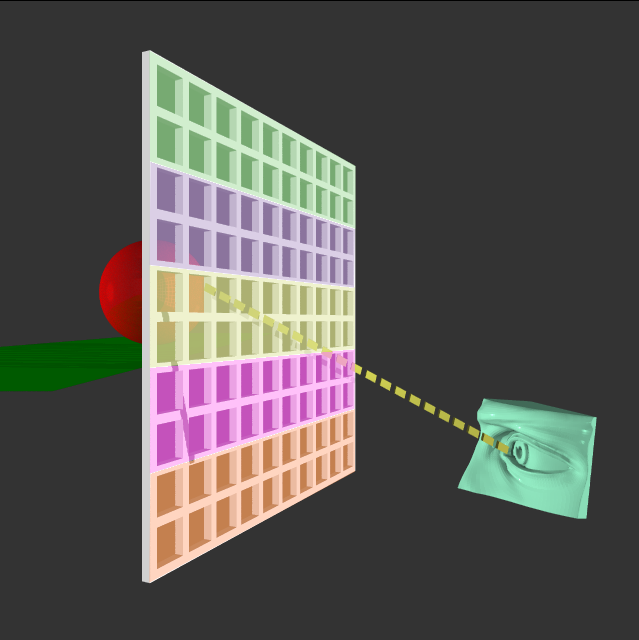
In this demo, we start with a single thread in the pool, change to 16 threads and then increase to 32. You'll notice in the resource manager that the other cores are not active with a single thread and the utilization increases as we add more threads.
Code Review
Each thread has a state machine that controls the execution. The threads do not need mutual exclusion since they only access memory within their partition.
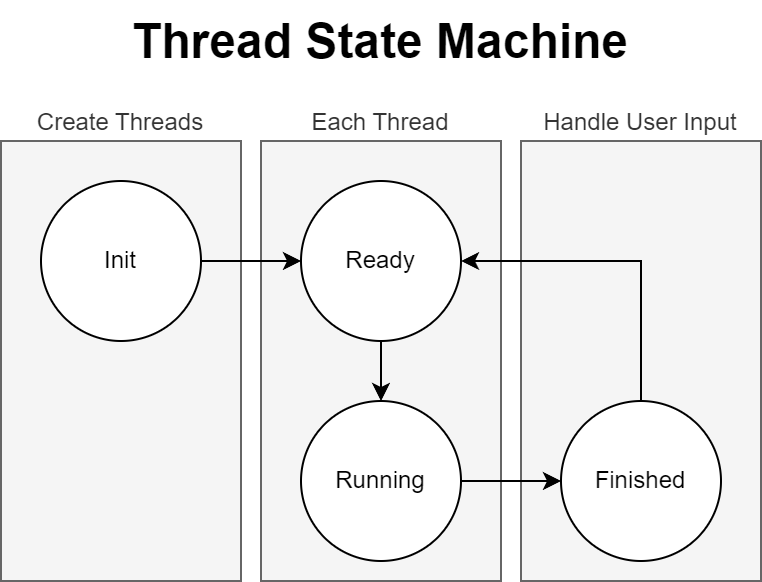
At the beginning of the process, the scene is partitioned and a thread is created for each partition.
void
AllocatePartitions(environment_t *env, scene_t *scene, viewport_t *vp, bvh_state_t *bvhState){
displayPart = (display_partition_t**)calloc(scene->settings.numberOfThreads, sizeof(display_partition_t));
for(int i = 0; i < scene->settings.numberOfThreads; i++){
displayPart[i] = (display_partition_t*) calloc(1, sizeof(display_partition_t));
displayPart[i]->status = WS_INIT;
displayPart[i]->thread = SDL_CreateThread(
RayTracePartition,
"",
displayPart[i]);
}
InitDisplayPartitions(env, scene, vp, bvhState);
}
The function that the thread is executing performs a lot of work, but here are the relevant parts of the code. Each thread busy waits for the state to move into the ready state.
int RayTracePartition(void *data) {
while(true){
display_partition_t *partition = (display_partition_t*)data;
if (partition->status != WS_READY){
SDL_Delay(1);
continue;
}
bitmapSettings_t *bitmap = partition->env->bitmap;
viewport_t vp = partition->viewport;
scene_t *scene = partition->scene;
bvh_state_t *bvhState = partition->bvhState;
partition->status = WS_RUNNING;
...
}
Threads move into the WS_READY state once the partition information is added or updated. This happens as part of the InitDisplayPartitions function.
for(int i=0; i < scene->settings.numberOfThreads; i++) {
// Generate unique data for each thread to work with.
displayPart[i]->yStart = yStart;
displayPart[i]->yEnd = yStart+yStep;
displayPart[i]->env = env;
displayPart[i]->viewport = *vp;
displayPart[i]->scene = scene;
displayPart[i]->bvhState = bvhState;
displayPart[i]->status = WS_READY;
yStart += yStep;
assert(displayPart[i]->thread != NULL);
}
In the main thread of the program, it waits for all threads to complete before processing user input.
// Wait until all workers have finished.
*complete = true;
for(int i = 0; i < scene->settings.numberOfThreads; i++){
if (displayPart[i]->status != WS_FINISHED)
*complete = false;
}
if (*complete){
HandleUpdates(env, scene, &bvhState);
}
Boss/Worker
One thing to notice at the end of the demo is one thread is working really hard trying to finish its partition while the other ones are idle. Our main thread changes some state and assigns task kinda like a Boss but not a very good one. Can the Boss identify idle threads and assign work for them to do? Since we know finished threads and running threads based on each thread's state machine, a finished thread can be assigned half of the work of a running thread. Let's add a new function Repartition to the boss thread that runs on a defined interval.
Before re-partitioning
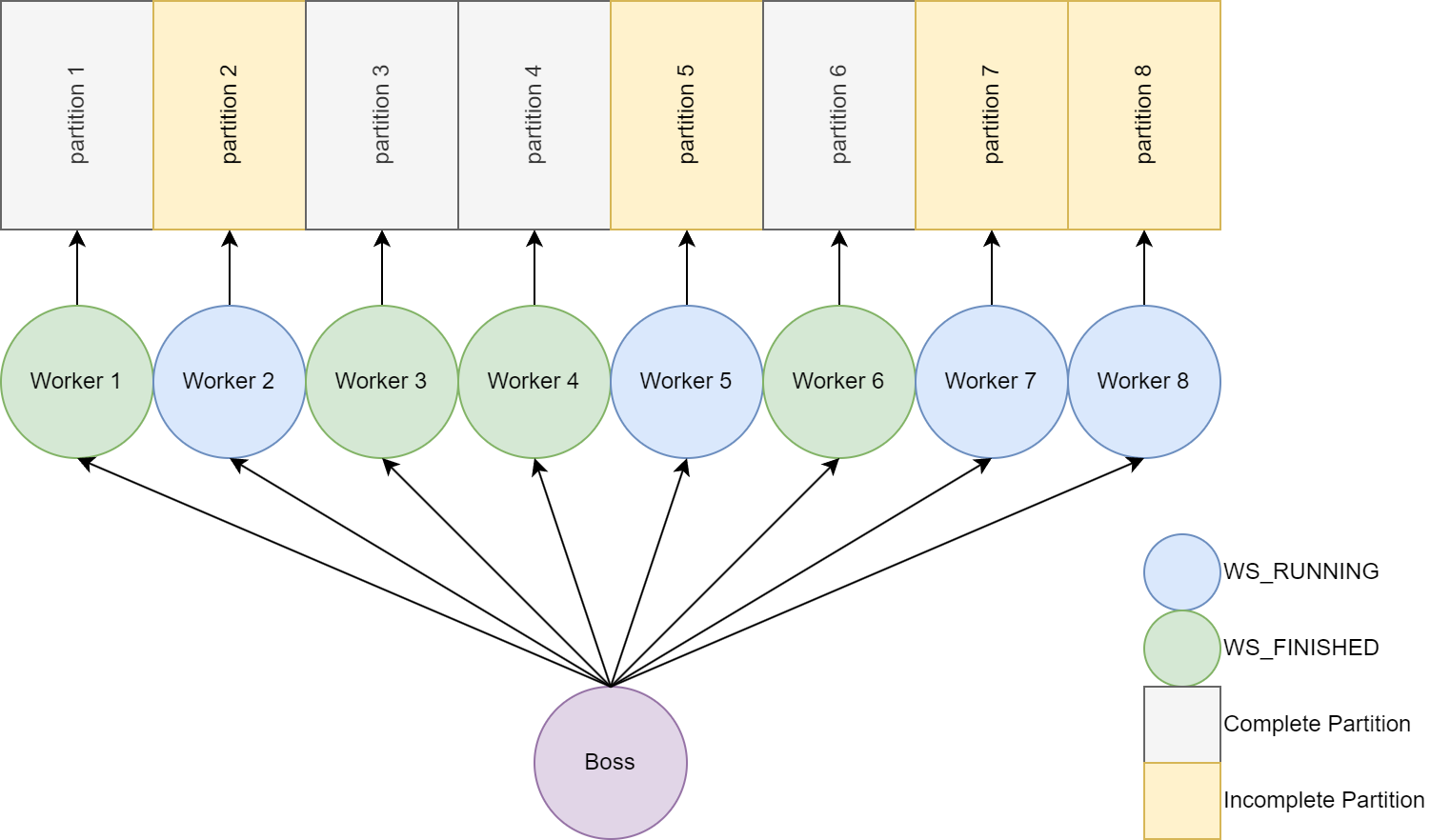
After re-partitioning
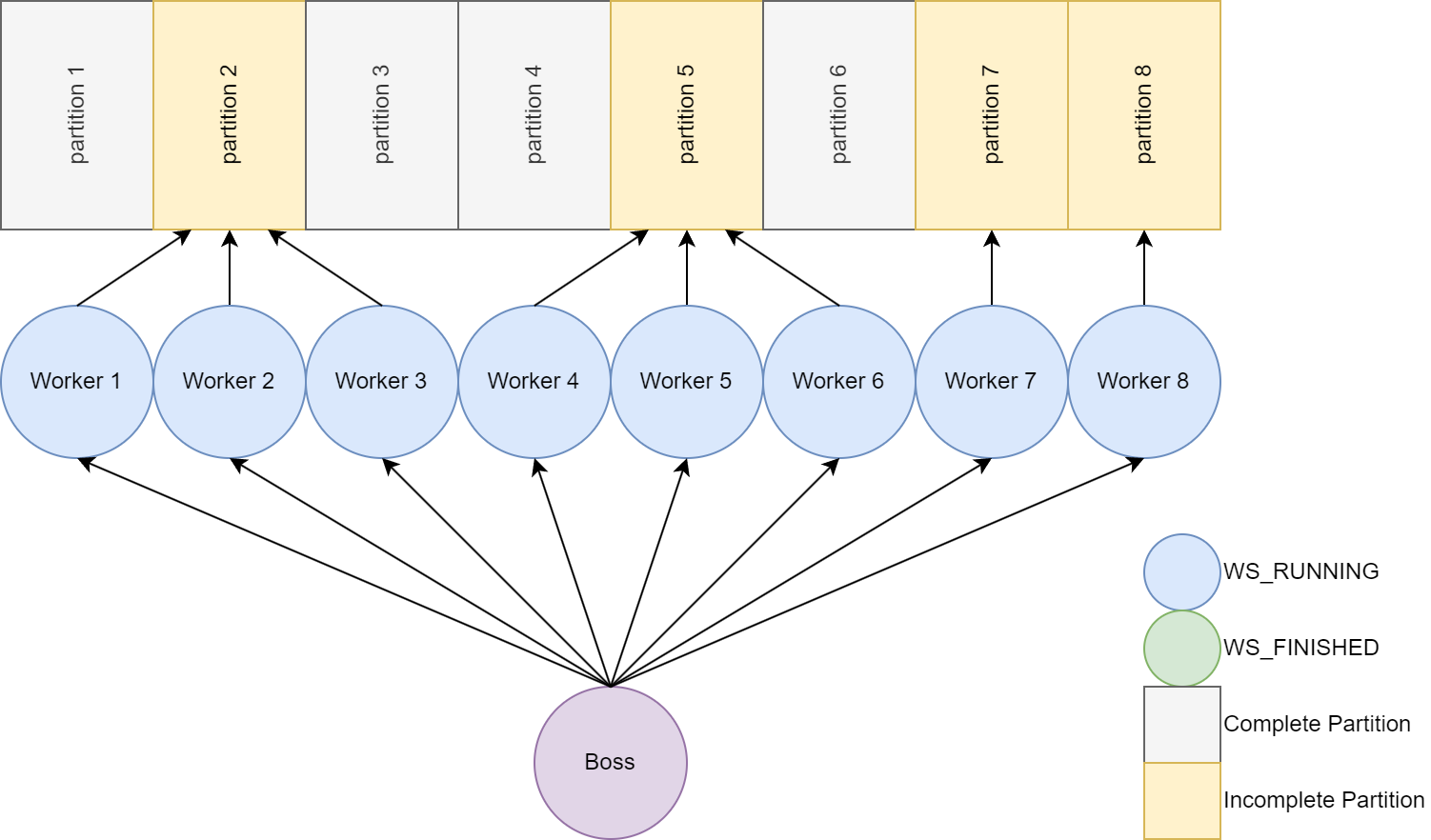
Repartition code changes
The code changes are pretty straightforward, for each running thread we check to see if we have a free thread available and divide the work. The pos member of the worker contains the current partition dimensions and position of the renderer horizontally. The partition is split vertically by defining oldEnd and newEnd. Then two new positions are created and sent to the workers incoming message queue.
void
Repartition(scene_t *scene, int_list_t *freeList){
int k = 0;
for(int i = 0; i < scene->settings.numberOfThreads; i++){
if (displayPart[i]->status == WS_RUNNING){
if (k < freeList->size){
int wid = displayPart[i]->id;
int fid = freeList->ids[k++];
int dy = max(1, displayPart[wid]->pos.yEnd - displayPart[wid]->pos.yStart);
int oldEnd = displayPart[wid]->pos.yEnd;
int newEnd = displayPart[wid]->pos.yStart + (dy/2);
position_t running;
position_t free;
running.x = displayPart[wid]->pos.x;
running.xEnd = displayPart[wid]->pos.xEnd;
running.yStart = displayPart[wid]->pos.yStart;
running.yEnd = newEnd;
free.x = displayPart[wid]->pos.x-1;
free.xEnd = displayPart[wid]->pos.xEnd;
free.yStart = newEnd;
free.yEnd = oldEnd;
AppendPosList(&displayPart[wid]->incoming, running);
AppendPosList(&displayPart[fid]->incoming, free);
}
}
}
}
Here is the extended completion checking code that builds the free list of threads that are finished.
freeList.size = 0;
*complete = true;
for(int i = 0; i < scene->settings.numberOfThreads; i++){
if (displayPart[i]->status != WS_FINISHED){
*complete = false;
}
else {
assert(freeList.size < freeList.maxSize);
freeList.ids[freeList.size++] = i;
}
}
Having an incoming message queue for each worker allows for isolation of locking to a specific thread.
#include "SDL.h"
...
struct position_t {
int yStart;
int yEnd;
int x;
int xEnd;
};
struct lockable_pos_list_t {
int size;
int maxSize;
position_t *pos;
SDL_mutex *listMutex;
SDL_cond *listCondVar;
};
struct display_partition_t{
int id;
position_t pos;
environment_t *env;
viewport_t viewport;
scene_t *scene;
worker_status_t status;
SDL_Thread *thread;
bvh_state_t *bvhState;
lockable_pos_list_t incoming;
};
void
AppendPosList(lockable_pos_list_t *list, position_t pos){
SDL_LockMutex(list->listMutex);
assert(list->size < list->maxSize);
list->pos[list->size++] = pos;
SDL_UnlockMutex(list->listMutex);
SDL_CondSignal(list->listCondVar);
}
A conditional variable on the incoming queue allows for the worker to wait for a signal instead of busy waiting on WS_READY.
int RayTracePartition(void *data) {
while(true){
display_partition_t *partition = (display_partition_t*)data;
SDL_LockMutex(partition->incoming.listMutex);
while (partition->incoming.size <= 0){
SDL_CondWait(partition->incoming.listCondVar, partition->incoming.listMutex);
}
partition->pos = partition->incoming.pos[partition->incoming.size-1];
partition->incoming.size = 0;
SDL_UnlockMutex(partition->incoming.listMutex);
...
The incoming queue makes handling a partition update to a WS_RUNNING thread simple too. The latest position is pulled off of the queue and the current partition of the worker is updated.
for (; partition->pos.x < partition->pos.xEnd && run; partition->pos.x++){
uint32_t lastColor = 0;
for(int y = partition->pos.yStart; y < partition->pos.yEnd && run;){
SDL_LockMutex(partition->incoming.listMutex);
if (partition->incoming.size > 0){
partition->pos = partition->incoming.pos[partition->incoming.size-1];
partition->incoming.size = 0;
y = partition->pos.yStart;
}
SDL_UnlockMutex(partition->incoming.listMutex);
Repartition Demo
In this scene I'm purposely leaving the top half of the image empty so those threads will finish before the bottom half of the image.
The demo looks good, but how are we sure that it's utilizing the assigned threads? On Linux perf stat can be used to look at cpu utilization. On my Windows box I have a AMD processor and I'm using micro-pref to view the utilization.
My processor has 12 cores and, in the below diagram without re-partitioning, 12 threads are only used a small percentage of the time.
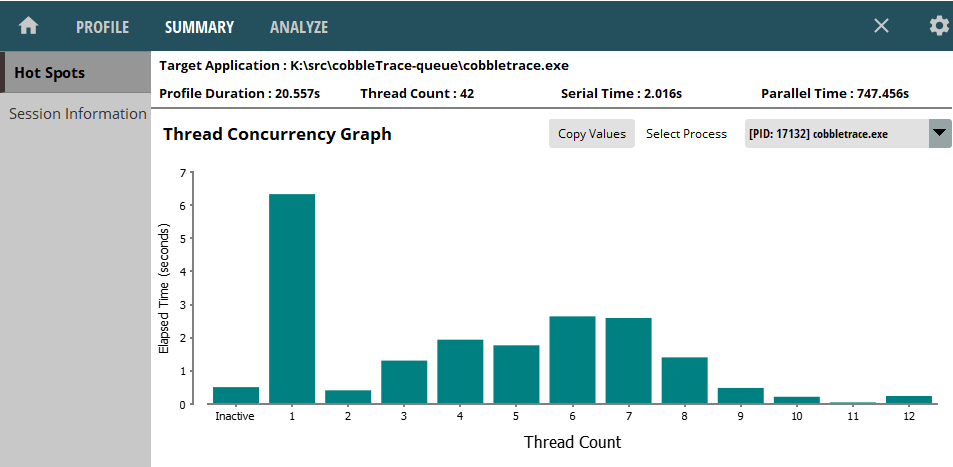
Once we start re-partitioning you can see all 12 cores are used the majority of the time.
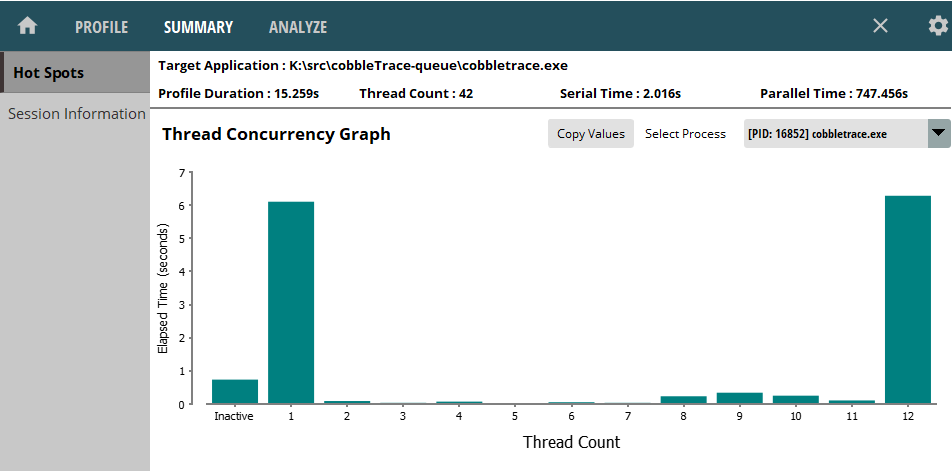
Thread number 1 is running for a long time because I haven't added multi-threading to the code that loads objects yet.
Libraries
I thought it would be fun to use my toy Ray Tracer to discuss threading patterns but if you're wanting to do serious Ray Tracing look into embree or optix. Embree is using the TBB library for multi-threading. TBB can take care of the partitioning for us automagically by providing a set of parallel language constructs. Below is a demo of the ray tracer using TBB instead of the custom repartitioner.
The custom thread pool and boss/worker code can be removed an replaced with:
class parallel_task {
public:
void operator()(const oneapi::tbb::blocked_range<int> &r) const {
bitmapSettings_t *bitmap = env->bitmap;
for (int y = r.begin(); y != r.end(); ++y) {
for (int x = xStart; x < xStop; x+=r.grainsize()) {
RenderOnePixel(x, y, scene, bitmap, vp, &bvhState);
}
}
}
parallel_task() {}
};
int TbbThread(void *data) {
int gs = (scene->settings.subsampling) ? 4 : 1;
oneapi::tbb::parallel_for(oneapi::tbb::blocked_range<int>(yStart, yStop, gs),
parallel_task(),
oneapi::tbb::auto_partitioner());
while(true){
if(HandleUpdates(env, scene, &bvhState)){
oneapi::tbb::parallel_for(oneapi::tbb::blocked_range<int>(yStart, yStop, gs),
parallel_task(),
oneapi::tbb::auto_partitioner());
}
}
}
It also utilizes all cores throughout rendering the scene.
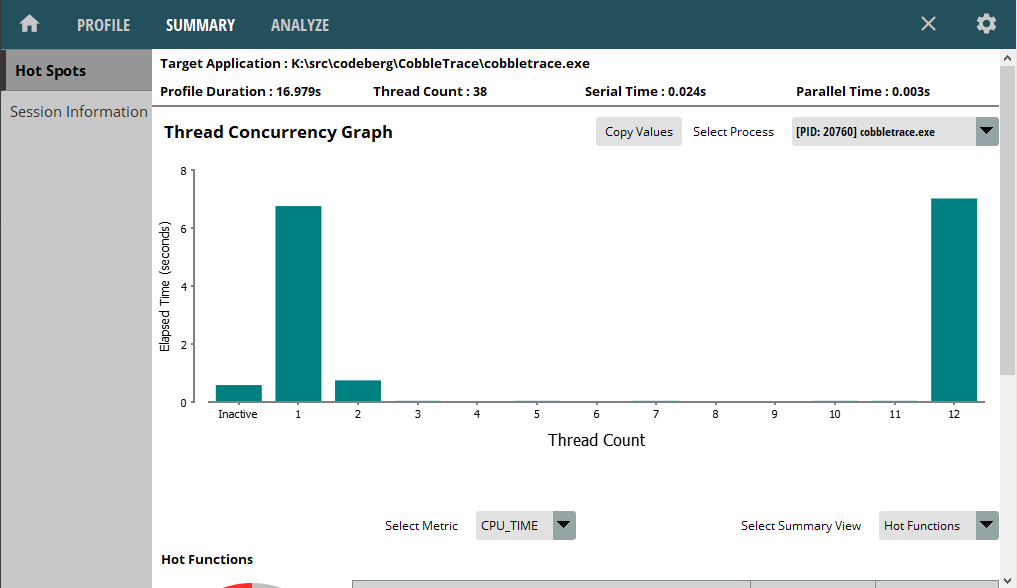
The complete refactor is here.
Conclusion
Embarrassingly Parallel programs can be extended quickly to take advantage of multiple cores. Adding a primary thread to manage the work can allow for control over the thread pool such as adjusting work assigned to a thread to increase utilization. Also, libraries exist to make this process easy.
Reference
- Computer Graphics From Scratch
- Glassner's Ray Tracing
- UC Davis Ray Tracing
- Scratch A Pixel
- jbikker's BVH
- Cobble Trace
- The Standford Models
- SDL Category API
Mapping between Birrell, C++ and SDL
| Birrell | C++ | SDL |
|---|---|---|
Tread Creation Fork | std::thread constructor | SDL_CreateThread |
Join | thread.join | SDL_WaitThread |
Fork | thread.detach | SDL_DetachThread |
Wait(m: Mutex; c: Condition) | condition_variable.wait(unique_lock | SDL_CondWait |
Signal(c: Condition) | condition_variable.notify_one() | SDL_CondSignal |
Broadcast(c: Condition) | condition_variable.notify_all() | SDL_CondBroadcast |
LOCK | mutex.lock() | SDL_LockMutex |
unlock happens when exiting LOCK scope | mutex.unlock() | SDL_UnlockMutex |