
Enterprise Ray Tracing
2024-07-15 05:20:00
Introduction
I thought it would be fun to use the ray tracer example again to show how the patterns from the Birrell paper can be applied to an enterprise setting. That way I can extend the ideas from part one and part two using containers, Kubernetes and Kafka.
Containerized Ray Tracer
Java Ray Tracer
To make it legit, the first thing we need is a Java application so I ported the Ray Tracing in One Weekend Ray Tracer to java. The only additions I have made are support for triangles, for scenes to be specified using JSON and for the tracer to work on specific partitions of the scene. I'll cover the scene files in a little more detail below. It is really slow since zero optimizations have been made.
Parallel For Loop
The partition change is basically the same as the one from the previous post. One difference this time is the communication happens through environment variables:
- What is the name of the file that should contain this partition? (
ER_OUTPUT_FILE) - How many total partitions are there? (
ER_NUMBER_PARTITIONS) - Which partition should this run of the program render? (
ER_PARTITION_INDEX)
The render loop focuses on a single partition:
public void render(IHittable world, String outputFileName,
Partition partition, int partitionIndex) throws Exception{
init();
FrameBuffer fb = new FrameBuffer(imageWidth, imageHeight);
for(int y = partition.getHeightStart(partitionIndex);
y < partition.getHeightStop(partitionIndex);
y++){
for(int x = partition.getWidthStart(partitionIndex);
x < partition.getWidthStop(partitionIndex);
x++){
Color pixelColor = new Color(0.0, 0.0, 0.0);
for(int sample = 0; sample < samplesPerPixel; sample++){
Ray r = getRay(x, y);
pixelColor.add(rayColor(r, maxDepth, world));
}
pixelColor.scale(pixelSamplesScale);
fb.setPixel(x, y, pixelColor);
}
}
fb.save(outputFileName);
}
A simple Docker container image can be created of the Ray Tracer using this definition:
FROM openjdk:latest
ARG tag=0.0.1
COPY target/enter-ray-${tag}.jar application.jar
RUN mkdir /output
RUN echo "Output directory created"
ENV ER_OUTPUT_FILE="/output/dockertest.png"
RUN echo "Env variable $ER_OUTPUT_FILE"
ENTRYPOINT ["java", "-jar", "application.jar"]
A shell script is used to simulate a parallel for loop. Something like this powershell:
param (
[string]$tag = "0.1.0",
[int]$numParts=1,
[string]$localOutput="//k/src/threads/enter-ray"
)
$mount=$localOutput+":/output"
$mount
for ($i = 0; $i -lt $numParts; $i++){
docker run -v $mount --env ER_NUMBER_PARTITIONS=$numParts --env ER_PARTITION_INDEX=$i --env ER_OUTPUT_FILE=/output/er-part-$i.png docker-enter-ray:$tag &
}
or bash:
#!/bin/bash
tag=$1
srcdir=~/src/threads/enter-ray
numParts=$2
upperBound=$(($numParts - 1))
for i in $(seq 0 $upperBound)
do
docker run -v ~/src/threads/enter-ray:/output --env ER_NUMBER_PARTITIONS=$numParts --env ER_PARTITION_INDEX=$i --env ER_OUTPUT_FILE=/output/er-part-$i.png docker-enter-ray:$tag &
done
In Docker Desktop you'll see multiple parallel instances of the container running. Each instance is rendering a different partition. Be patient it is slow.
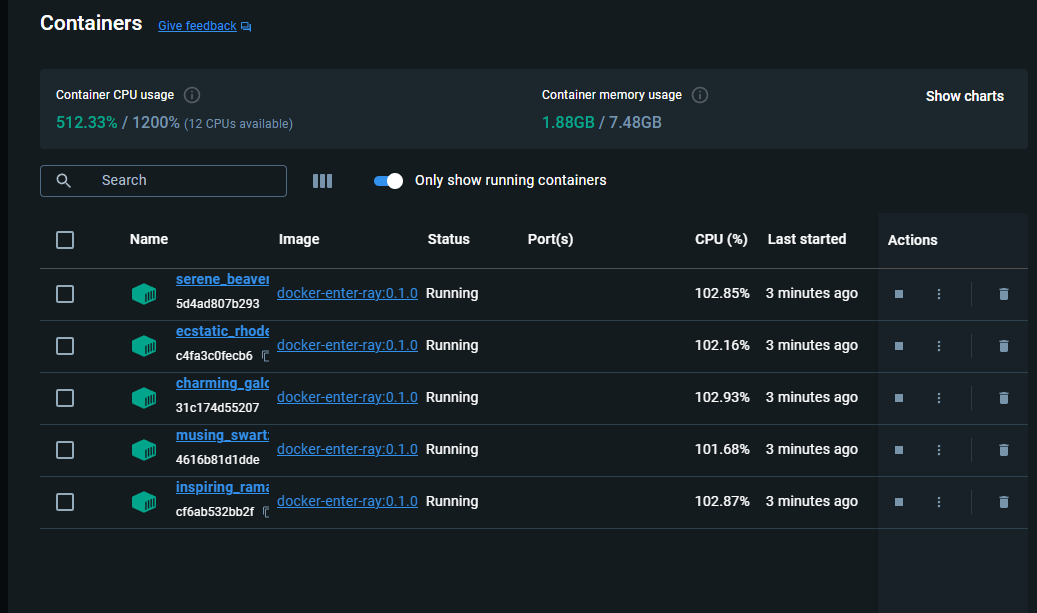
At the end of the run, you will notice in the output directory a different image of the same size is created for each partition. Anything not rendered has a clear alpha channel.



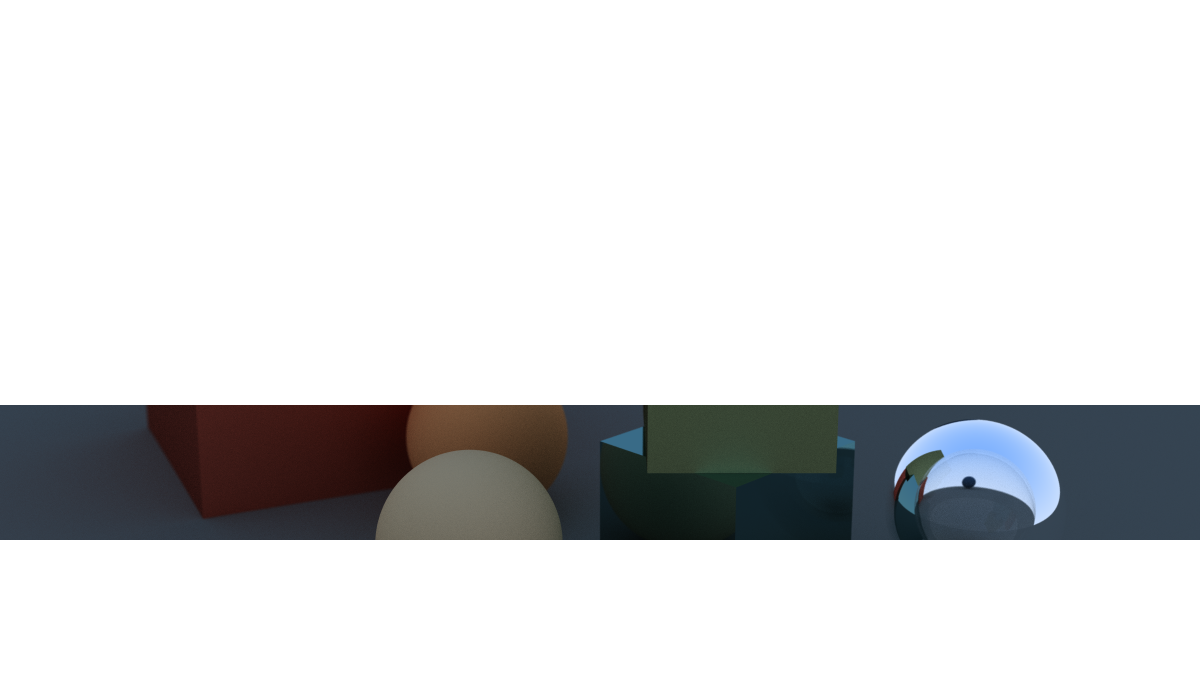

ImageMagick is used to reduce these partitions to a single image:
#!/bin/bash
# Use imagemagick to combined the partitions
convert er-part-*.png -background None -flatten $1
creating the final image:

The source code for this version is in the docker-image directory.
Kubernetes
Since the Ray Tracer is an unoptimized java app, and every vector operation requires a heap allocation due to the way the javax.vecmath.Vector3d library is implemented, the tracer starts to run into memory issues on a single machine with more than a handful of partitions. One solution is to just run the tracer on multiple machines to get more cores and ram. This could be accomplished by ssh-ing into each machine, copying the container, changing the parallel for loop to run over a specific range and then collecting the partitions from each machine when rendering is done.
Another option is to use an orchestration tool like Kubernetes. If you're not familiar with k8s (Kubernetes), it allows for Nodes (physical machines) to be grouped together as a cluster. You can then create Pods which are container instances running on one or more nodes. Some nodes in the cluster function as a control plane which start/stop and scale pods, among other things. This can be thought of as the "Boss" in the "Boss/Worker" pattern.
At this point we can recreate the situation we had in the last post but running on multiple machines.
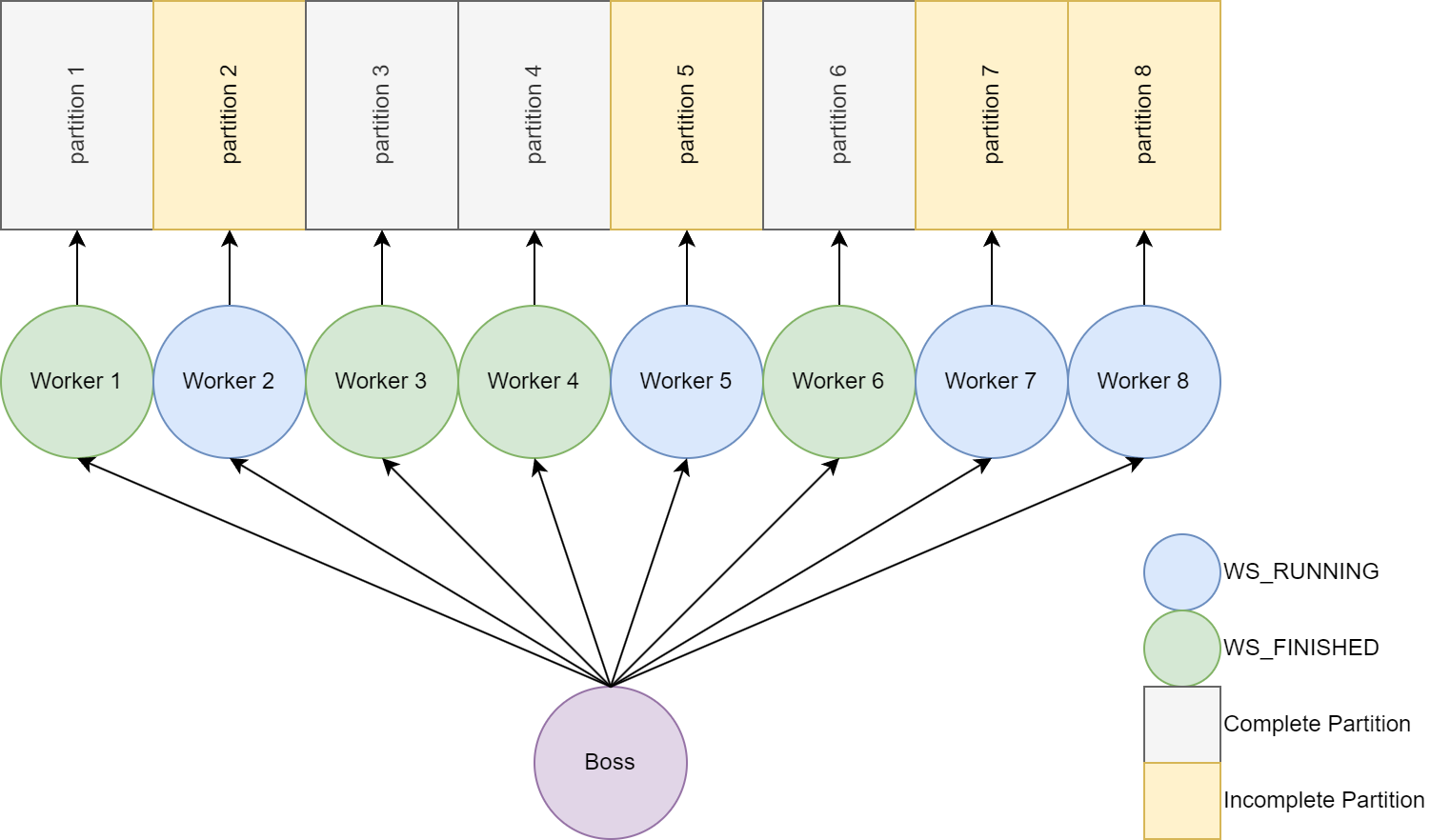
The boss in k8s knows what to execute based on the yaml files that you feed it. One thing you might be thinking is "How do we tell it to use a different partition for each worker"? K8s StatefulSets can be used since it will assign each pod a sticky identifier. This identifier is used to fix a partition to a specific Pod.
apiVersion: v1
kind: Service
metadata:
name: er-headless
spec:
selector:
app.kubernetes.io/name: enter-ray
clusterIP: None
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: enter-ray-statefulset
labels:
app: enter-ray
spec:
serviceName: er-headless
replicas: 15
selector:
matchLabels:
app: enter-ray
template:
metadata:
labels:
app: enter-ray
spec:
containers:
- name: enterray
image: hsilgnej/chimchim:docker-enter-ray
volumeMounts:
- mountPath: /output
name: output
env:
- name: ER_PARTITION_INDEX
valueFrom:
fieldRef:
fieldPath: metadata.labels['apps.kubernetes.io/pod-index']
- name: ER_NUMBER_PARTITIONS
value: "15"
- name: ER_OUTPUT_FILE
value: "/output/er_part_$(ER_PARTITION_INDEX).png"
imagePullSecrets:
- name: regcred
volumes:
- name: output
nfs:
server: digdug
path: /mnt/external/home/jeng/Pictures
securityContext:
runAsUser: 1001
fsGroup: 1001
A couple of things to point out in the yaml.
- I'm using an external drive on my digdug server to function as network attached storage which is mounted as
/outputon the pod. - The image
hsilgnej/chimchim:docker-enter-rayis being pulled from a private repo on Docker Hub. This requires animagePullSecrets. - The
ER_PARTITION_INDEXenvironment variable is being assigned the pod index usingmetadata.labels['apps.kubernetes.io/pod-index']
The source code for this version is in the k8s directory.
Kafka
Now that we can render 15 partitions at the same time, it would be nice if we could render different images. A scene file parser was added that allows for defining the scene using json. But how can we pass the image to the pods and have them render the correct partition? Kafka will be used as an incoming work queue. It also has the nice property of having partitions under the hood. If we can make sure that we write the scene to each partition in our queue, then we can use the StatefulSet from above to assign work to each of those partitions.
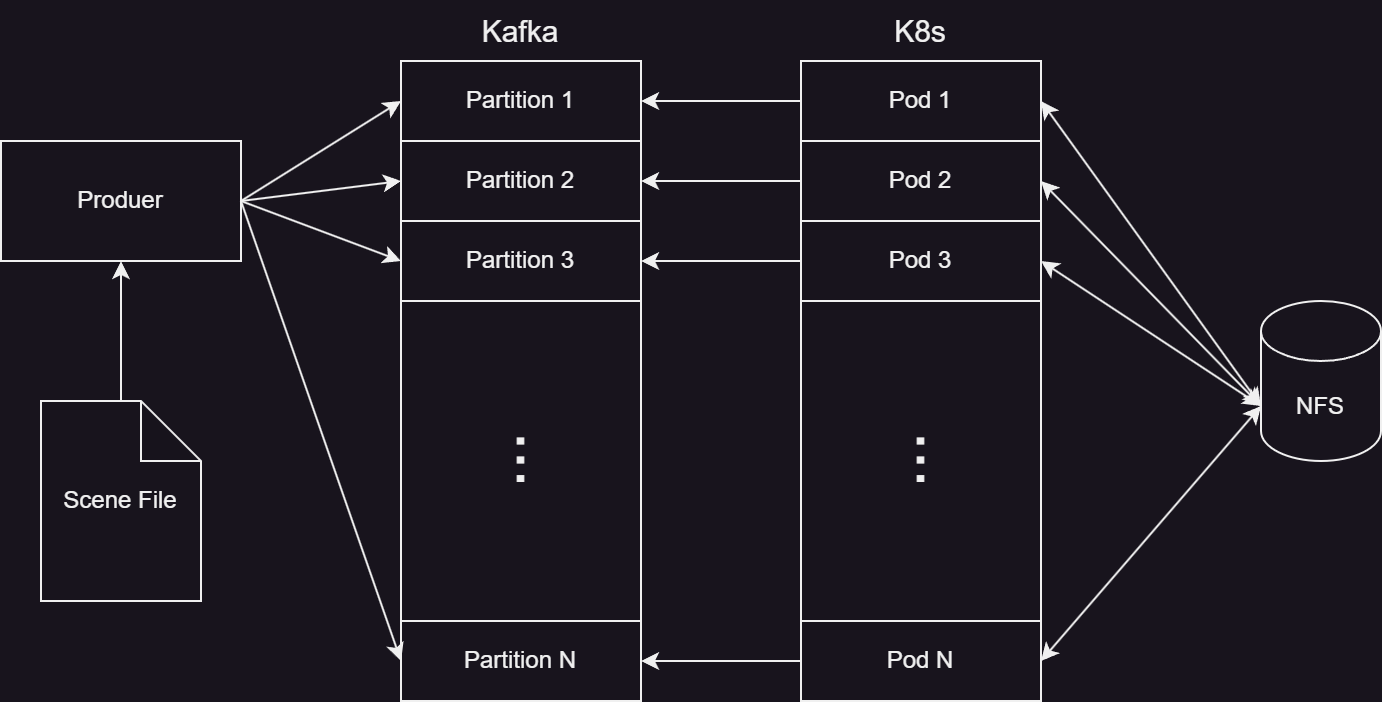
A change was made to the ray tracer so that it can act as a Kafka consumer. The partitionIndex from before is used when assigning the consumer's partition.
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
List<TopicPartition> partitionList = new ArrayList<TopicPartition>();
partitionList.add(new TopicPartition(topic, partitionIndex));
consumer.assign(partitionList);
A producer takes the scene file from the command line and writes a copy to each partition.
String sceneJson = loadJson(sceneFile);
Path path = Paths.get(sceneFile);
int partitions = getPartitions(sceneJson);
System.out.printf("Writing to %d partitions %n", partitions);
for(int i = 0; i < partitions; i++){
producer.send(new ProducerRecord<>(topic, i, path.getFileName().toString(), sceneJson));
}
For the StatefulSet definition, another volume was added to store the Kafka configuration. Also some environment variable changes were made: the ER_NUMBER_PARTITIONS variable is no longer needed and a variable was added to enable consumer mode.
Demo
To stress test this implementation I wrote a script that rotates the camera around the scene. Each file was ran through the producer and then I patiently waited. This screenshot shows what the topic looked liked during the rendering phase:
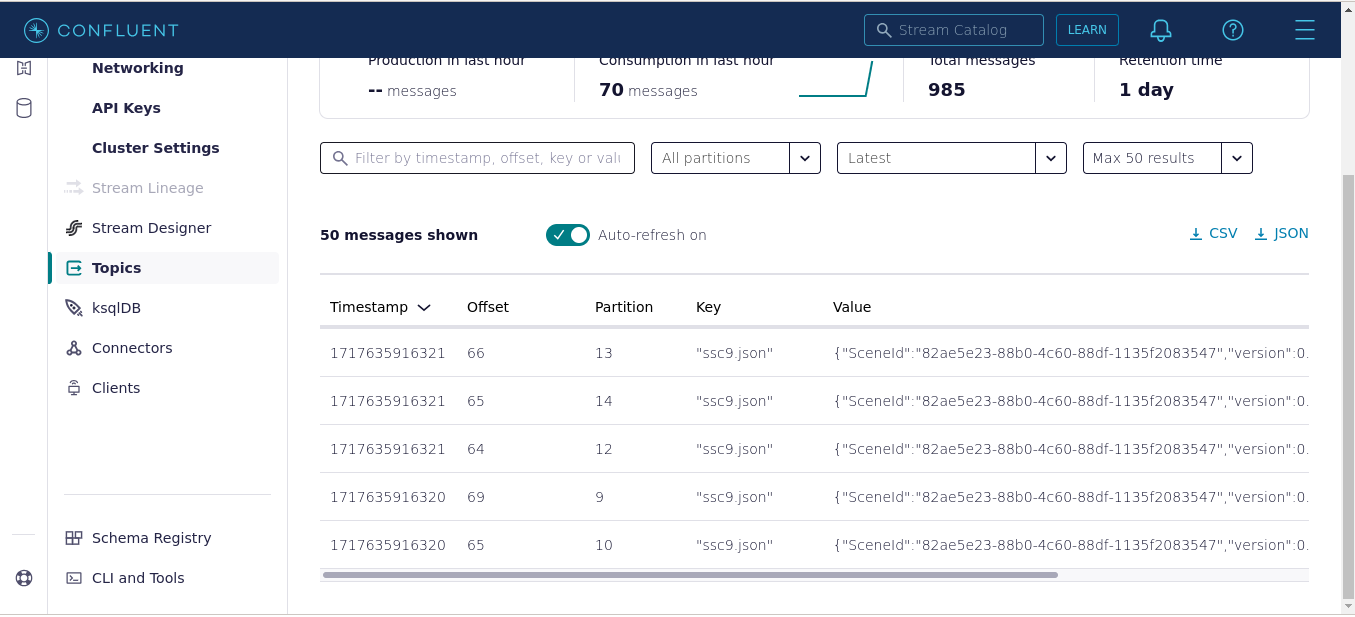
Here's the animation produced after reducing all of the partitions:
The source code for this version is in the kafka directory.
Pipeline
The design above has some limitations. What if you want to change the number of workers in your crew? What if you are tired of looking at log files to monitor progress? What if you'd like the script to reduce the partitions to run automatically? Let's revisit the Pipeline pattern from the Birrell paper and see what we can come up with.
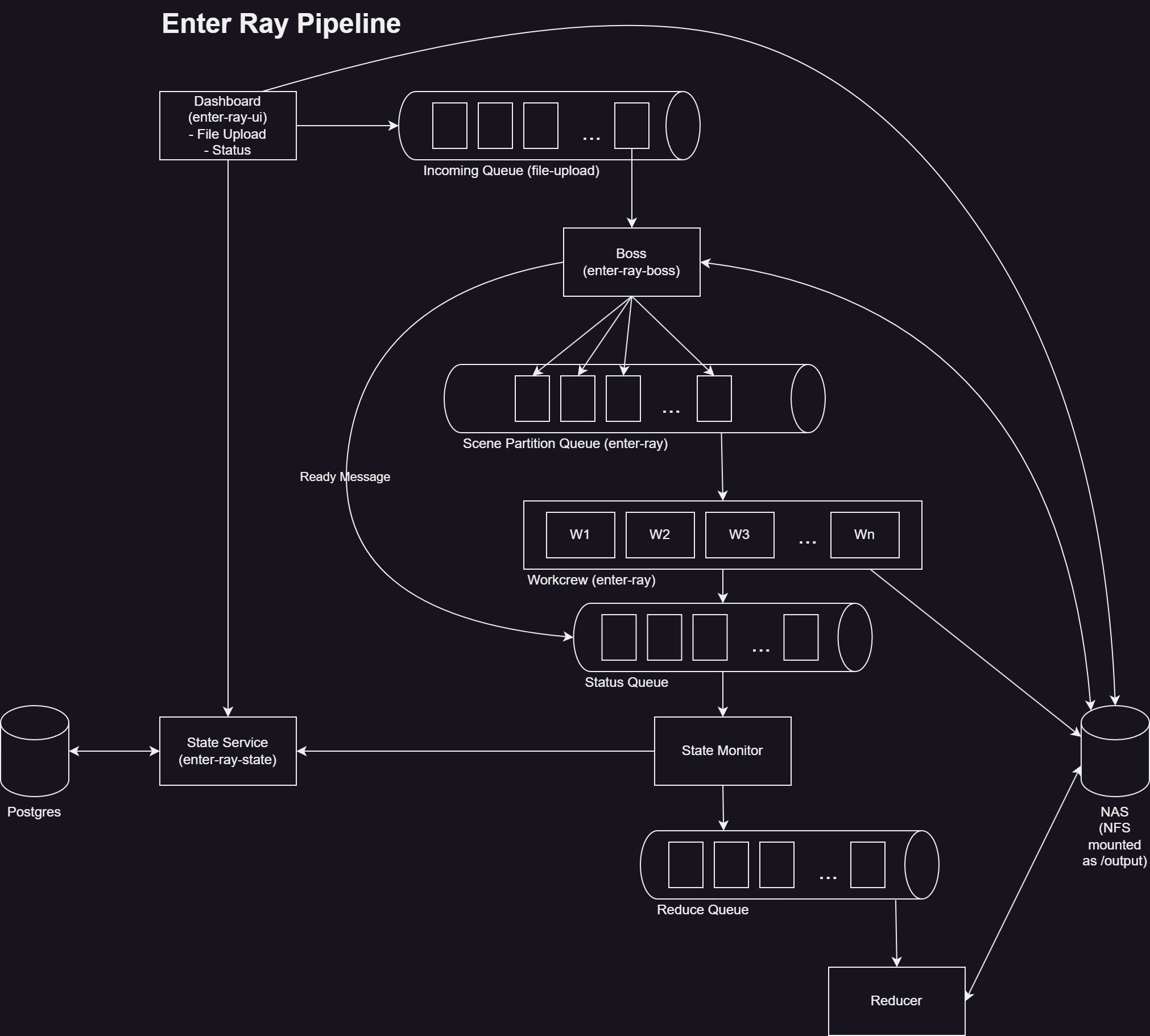
I ended up with the following pipeline stages in Kafka:
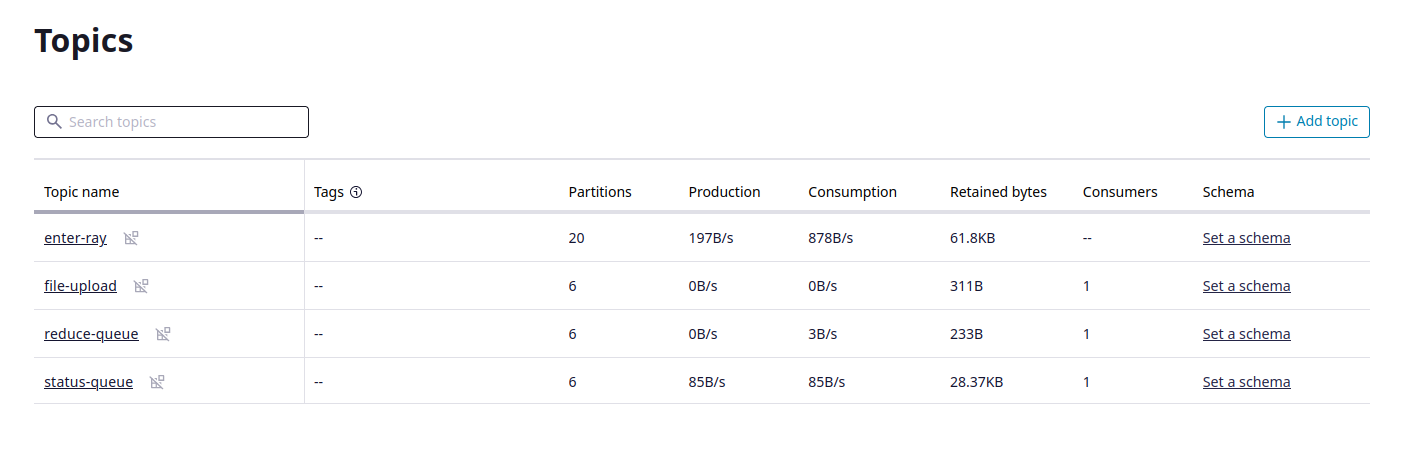
enter-ray-ui
The UI has a page to upload scene files in batch and a status monitoring page. The upload code is straight from the Spring Boot tutorials with some minor changes made to support multiple files. When a file is uploaded, it is placed in a shared location on the NAS and then placed on the incoming file queue.
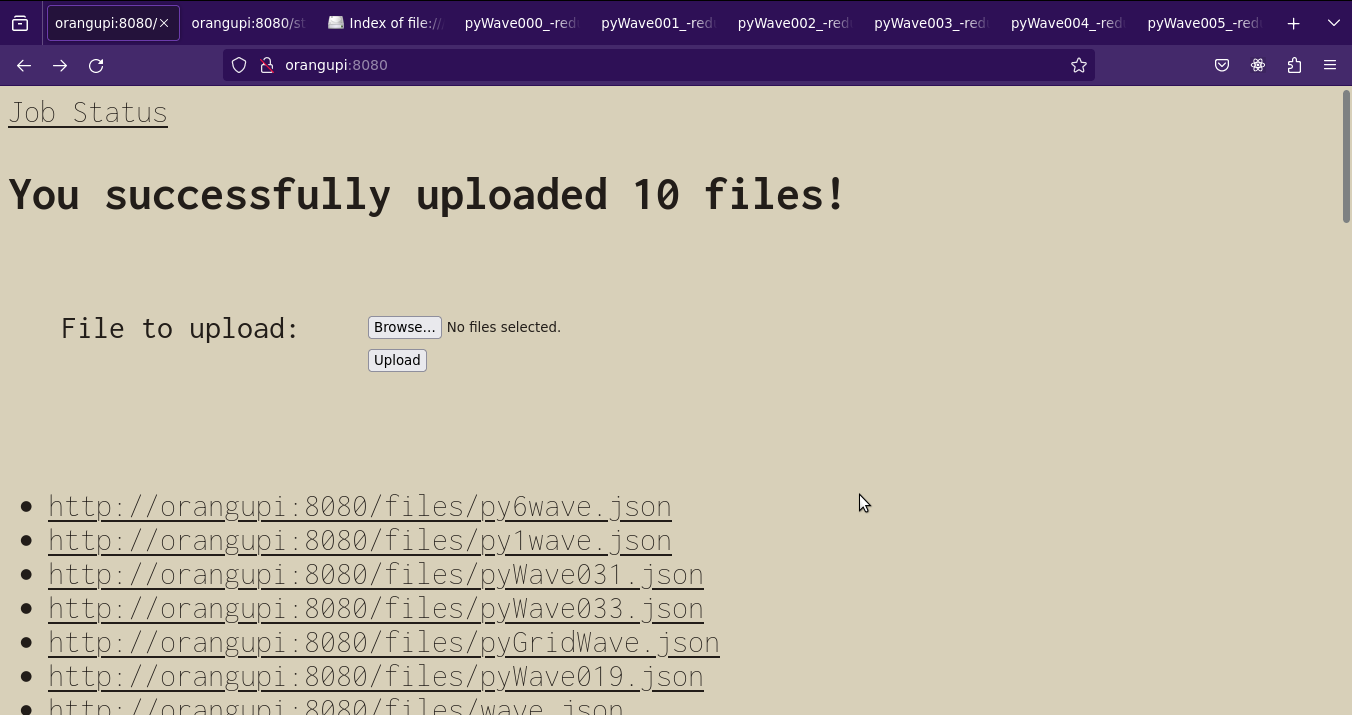
The status page shows which of the three statuses a partition is in: ready, running, or finished.
enter-ray-state
The ui pulls status information from a REST API that is offered by the enter-ray-state service. The enter-ray-state service also allows for updating the state and serves as the front-end to the status database. The database tracks the status for each partition. With atomic writes, and an added constraint on the state id, status updates do not get lost.
CREATE TABLE public.partition_state (
key bigint NOT NULL,
scene_id uuid NOT NULL,
partition_id integer NOT NULL,
total_partitions integer NOT NULL,
state_id integer NOT NULL,
update_time timestamp without time zone DEFAULT '1970-01-01 00:00:00'::timestamp without time zone NOT NULL,
file_prefix character varying(255) NOT NULL
);
CREATE RULE only_increase_state AS
ON UPDATE TO public.partition_state
WHERE (new.state_id <= old.state_id) DO INSTEAD NOTHING;
enter-ray-state-monitor
The state-monitor does the following:
- It pulls state messages published by the boss or the workers.
- It then creates the payload for the
enter-ray-stateAPI and POST or PATCHs the status. - It checks if the scene is complete by looking at all partition statuses for the current scene status being updated.
- If all statuses are
finished, it publishes a message for the reducer.
enter-ray-boss
The only real change made to the boss is that it gets the file to partition from the NAS based on an incoming file message instead of from a command line argument. One thing to note is that since we would like to utilize all of the cores in our work crew we need to be aware of the partitioner that is used. By default Kafka uses a sticky partitioner which is optimized for high message volume. In this use case we're not bound by message volume so it doesn't really help us. For that reason the boss makes sure it spreads the messages across partitions.
for(int i = 0; i < partitions; i++){
setPartitionIndex(sceneJson, i);
//These are CPU intensive workloads we do not want multiple parts of the scene
//to go to one partition. The default sticky partition strategy will do this.
//We want each consumer node to be fully utilized when rendering the scene.
int writePartition = i % numberOfTopicPartitions;
String key = path.getFileName().toString() + " - " + String.valueOf(i);
producer.send(new ProducerRecord<String,String>(outgoingTopic, writePartition, key, sceneJson.toString()));
printf("%s%n", gson.toJson(new SceneMessage(sceneJson, SceneMessageTypes.ready)));
eventProducer.send(gson.toJson(new SceneMessage(sceneJson, SceneMessageTypes.ready)));
printf("partition %d key %s%n", writePartition, key);
}
In this example of the partition assignment notice that each scene partition is aligned to a kafka partition:
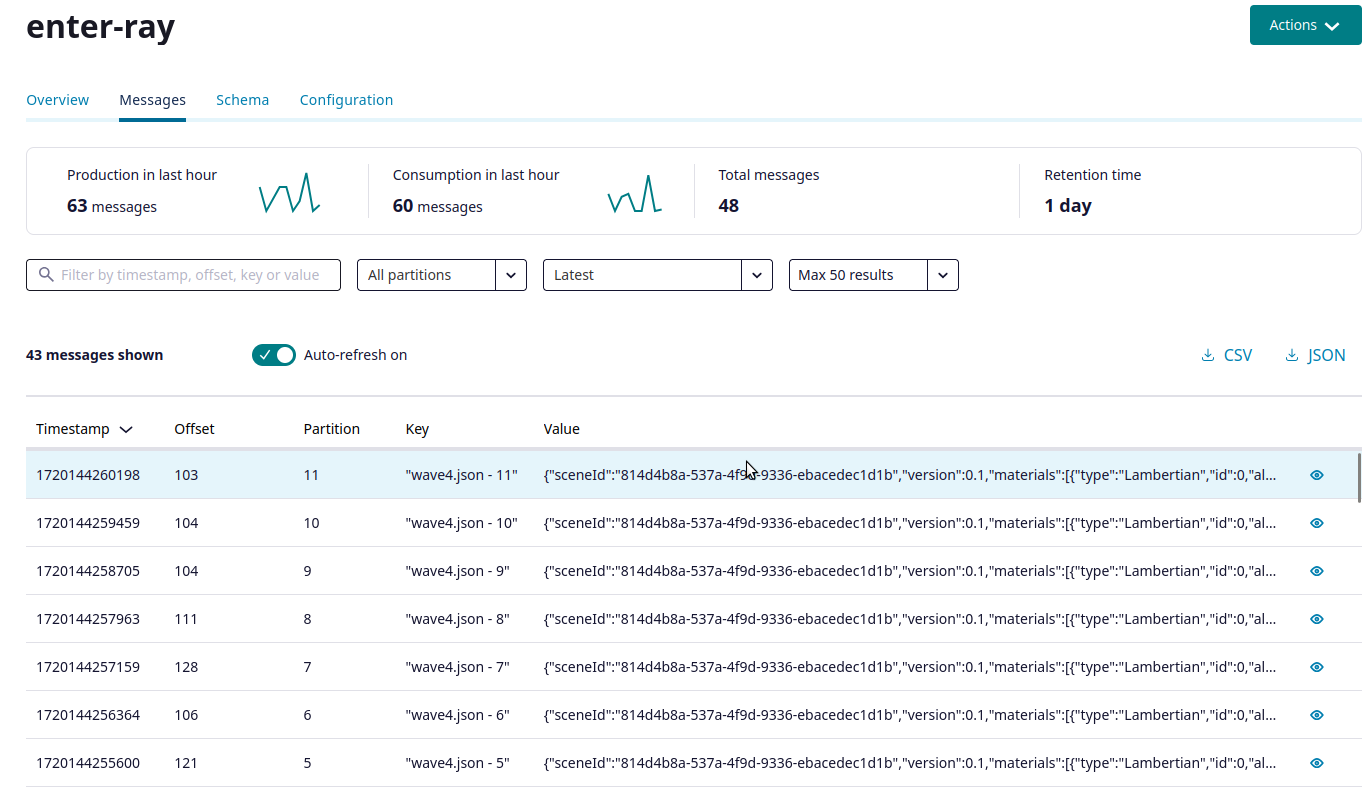
The boss also publishes the ready status message for each partition.
enter-ray
The major change that was made to the workers is that they subscribe to the Kafka topic instead of setting an assignment. Using subscribe means we can scale up or down the number of workers and still render all of the partitions.

As you can see here, the 12 workers get assigned 1 to 2 of the 20 Kafka partitions. For example the first one will read from partitions 2 and 3 and the second one will read from partition 10 and 11. Another note about this, to get the max throughput the scene definition would set max partition to the number of Kafka partitions for the Scene Partition Queue and a worker CPU would be assigned to each.
Each worker also publishes status messages. A running message at the start of rendering and a finished message when they're done.
enter-ray-reduce
I really didn't want to reimplement the flatten functionality of ImageMagick, so the reducer is using kcat (or kafkacat) as the reduce queue consumer.
#!/bin/sh
alias kcat=kafkacat
while true
do
prefix=`kcat -b pkc-619z3.us-east1.gcp.confluent.cloud:9092 -X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN -X sasl.username=$KAFKA_USER -X sasl.password=$KAFKA_PASSWORD -G reduce-group reduce-queue -o stored -e -c 1 -q`
if [ ! -z "$prefix" ]
then
echo "reducing $prefix"
convert $SHARED_DIR$prefix* -background None -flatten $SHARED_DIR/reduced$prefix-reduce.png
fi
sleep 2
done
Demo
This quick demo shows the UI and what the queues and consumers look like after a few runs.
Stress test
For a stress test I created a short wave animation that resulted in around 250 scenes. I had to lower the resolution some since I was running out of credits on Confluent.
The source code for this version is in the kafka-pipeline directory.
Conclusion
- Managing a Kubernetes cluster is a full time job.
- From Amdal's Law we know it is best to speed up the common case. I always suggest making that as fast as possible before thinking about throwing more cores or consumers at the problem.
- If you're curious about real render farms, checkout this overview of Pixar's RenderMan Tractor